Come Usare Git e GitHub: Guida per Principianti
Pubblicato da fran00

Che cosa è Git?
Git è un sistema di controllo versione distribuito (Distributed Version Control System o DVSC), ovvero un software che consente di gestire il codice sorgente di un progetto software durante lo sviluppo collaborativo senza bisogno del supporto di un server centrale. Grazie a Git i programmatori possono registrare ogni modifica che viene fatta al codice nel tempo, confrontare diverse versioni di uno stesso file, collaborare contemporaneamente a uno stesso programma per implementare nuove funzionalità senza interferire con il lavoro degli altri membri del team e fare molte altre cose che vedremo in questo articolo.
Git è open-source e può essere utilizzato su diversi sistemi operativi (tra cui Windows, macOS e Linux) ed è uno strumento davvero fondamentale per qualsiasi sviluppatore di software: lo utilizzano aziende importanti come Google, Microsoft, Twitter e Linkedin, ma può rivelarsi davvero utile anche per progetti molto più piccoli, perfino se sono portati avanti da un singolo sviluppatore.
Le funzionalità di Git sono davvero tantissime, in questo articolo esploreremo le più importanti facendo una panoramica degli argomenti che seguono:
- I repository di Git
- Come installare Git
- Configurare le informazioni utente di Git
- Configurare l’accesso a GitHub tramite GitHub CLI
- I comandi di Git
- Esempi di utilizzo di Git
Attenzione: potreste dover rivedere le varie sezioni di questo articolo più volte, per comprenderne il funzionamento nel dettaglio o come referenza per i singoli comandi. Questo è normale: evitate di scoraggiarvi! Vi consigliamo di mettere alle prova le conoscenze che apprenderete da subito, così da poterle rendere davvero vostre: per argomenti come questi nessuna guida sarà mai abbastanza da sola quindi fate pratica!
I repository di Git
La funzionalità principale di Git sono i repository (in italiano “depositi”) o (in breve) repo, archivi digitali in cui viene conservato e gestito il codice sorgente di un progetto software e che tengono traccia delle modifiche apportate ai file nel corso tempo. Un repository consente di recuperare versioni precedenti, confrontare le differenze tra le versioni e collaborare contemporaneamente con altri sviluppatori in team senza interferire gli uni con gli altri.
I repository possono essere ospitati su diversi servizi di hosting che utilizzano Git come sistema di controllo versione, come GitHub, GitLab e Bitbucket. Questi strumenti consentono di condividere, collaborare e gestire i repository in modo più facile e efficiente attraverso interfacce web e strumenti di gestione del progetto. Noi in questo articolo vi spiegheremo come utilizzare Git tramite la piattaforma GitHub.
Nell'immagine potete vedere un esempio di repository ospitato su GitHub:
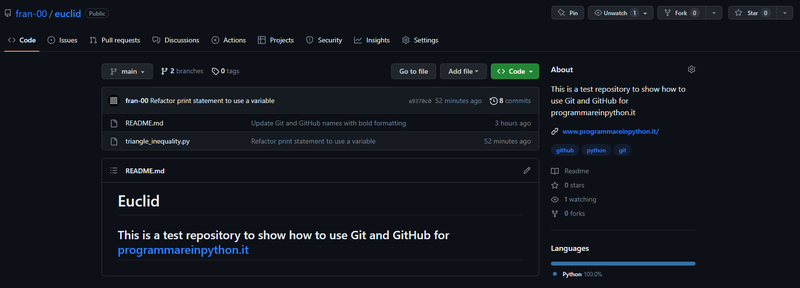
Come installare Git
Per prima cosa dobbiamo installare Git sul nostro sistema operativo. Verifichiamo che non lo sia già aprendo un terminale di sistema e dando il comando:
git --versionSe il comando non viene riconosciuto, dobbiamo procedere con l'installazione in base al sistema operativo che stiamo utilizzando.
Installare Git su Windows
Scaricate il file di installazione da questo link e installatelo come un qualsiasi programma:
Installare Git su Linux
Per installare Git da Bash o altra shell di sistema Linux, il comando da usare dipenderà dalla distribuzione utilizzata; Potete trovare i comandi per le principali distribuzioni a questo link. Ad esempio, se usate Debian o una distribuzione derivata come Ubuntu o Pop OS, il comando sarà:
sudo apt install gitInstallare Git su MacOS
Possiamo installare Git tramite il gestore di pacchetti HomeBrew:
brew install gitPotete trovare altri metodi di installazione a questo link.
Configurare le informazioni utente di Git
Come abbiamo accennato, Git ci permette di tener traccia delle varie modifiche fatte al progetto nel tempo. Per aiutarci a mantenere l'elenco di queste modifiche ordinato e utile, dobbiamo selezionare un nome e un indirizzo email tramite il comando git config —global. La configurazione globale (--global) ci consente di impostare queste informazioni una sola volta e di utilizzarle in tutti i repository Git sul nostro computer.
Scegliamo con cura il nome: sarà abbinato alle varie modifiche che farete e potrà essere visionato da eventuali collaboratori che avranno accesso allo stesso progetto. Io ho scelto lo stesso nome utente che utilizzo su GitHub, ma volendo potete anche utilizzare nome e cognome.
Per quanto riguarda l'indirizzo email, assicuratevi di utilizzare l'indirizzo email del vostro account GitHub: questo vi permetterà di aggiornare il vostro grafico delle attività sulla base delle varie modifiche che apporterete ai vostri repo (vedremo a breve come!)
Inserite la vostra email e il vostro username o nome + cognome in questo modo:
git config --global user.email "mail@esempio.com"
git config --global user.name "username / nome + cognome"A questo punto non ci verrà chiesta nessuna password, ma la prima volta che cercheremo di effettuare un'operazione che richiede l'autenticazione, come il push o il pull di un repository privato (vedremo nel corso di questo articolo a che cosa servono questi comandi) Git la chiederà insieme all’username per accedere alla piattaforma di hosting a cui ci stiamo collegando, che nel nostro caso è GitHub.
Come spiegato nella documentazione di GitHub, ci sono diversi modi per autenticarsi: volendo potete anche semplicemente creare un personal access token, che funge a mo' di password d'accesso e va ripetuto ogni volta che è necessario autenticarsi per fare qualsiasi operazione.
Noi in questa guida seguiremo una delle procedure più semplici e comode installando GitHub CLI.
Configurare l’accesso a GitHub tramite GitHub CLI
GitHub CLI è un’interfaccia a riga di comando che consente di interagire con GitHub eseguendo molte delle stesse operazioni che si possono fare sul sito tramite un terminale. Installiamola sul nostro computer.
Come installare GitHub CLI
Su Windows
Su Windows possiamo scaricare il file di installazione direttamente dal sito ufficiale.
Su Linux
Se usate altre distribuzioni Linux trovate la guida nel repo, per Debian e Ubuntu copiate e incollate nel terminale il seguente comando:
type -p curl >/dev/null || (sudo apt update && sudo apt install curl -y)
curl -fsSL https://cli.github.com/packages/githubcli-archive-keyring.gpg | sudo dd of=/usr/share/keyrings/githubcli-archive-keyring.gpg \
&& sudo chmod go+r /usr/share/keyrings/githubcli-archive-keyring.gpg \
&& echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/githubcli-archive-keyring.gpg] https://cli.github.com/packages stable main" | sudo tee /etc/apt/sources.list.d/github-cli.list > /dev/null \
&& sudo apt update \
&& sudo apt install gh -ySu MacOS
Potete installarlo via HomeBrew:
brew install gh
brew upgrade ghAutenticarsi con GitHub CLI
Adesso inseriamo il seguente comando e ci verrà chiesto dove vogliamo autenticarci. Selezioniamo GitHub.com e premiamo INVIO.
gh auth login
# output
? What account do you want to log into? [Use arrows to move, type to filter]
> GitHub.com
GitHub Enterprise ServerCi verrà chiesto quale protocollo di sicurezza preferiamo utilizzare quando usiamo Git: per semplicità scegliamo HTTPS.
? What is your preferred protocol for Git operations? [Use arrows to move, type to filter]
> HTTPS
SSHCi verrà chiesto se vogliamo autenticarci con le credenziali di GitHub. Rispondiamo “Y” e ci verrà chiesto in che modo vogliamo autenticarci: selezioniamo con il browser e questo verrà aperto automaticamente, oppure ci verrà mostrato un link in cui andare. Oltre ad inserire la password di GitHub dovremo inoltre aggiungere un codice usa e getta (one-time code) che ci verrà fornito dalla CLI.
? Authenticate Git with your GitHub credentials? (Y/n)
> Y
? How would you like to authenticate GitHub CLI? [Use arrows to move, type to filter]
> Login with a web browser
Paste an authentication token
! First copy your one-time code: XXXX-XXXX
Press Enter to open github.com in your browser...Inseriamo il codice usa e getta (one-time code):
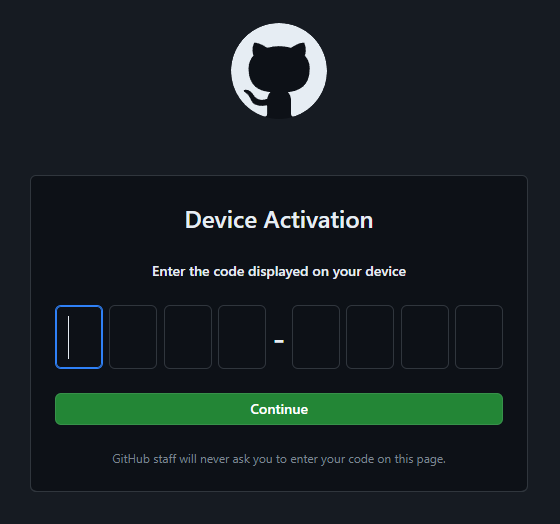
Autorizziamo GitHub CLI:
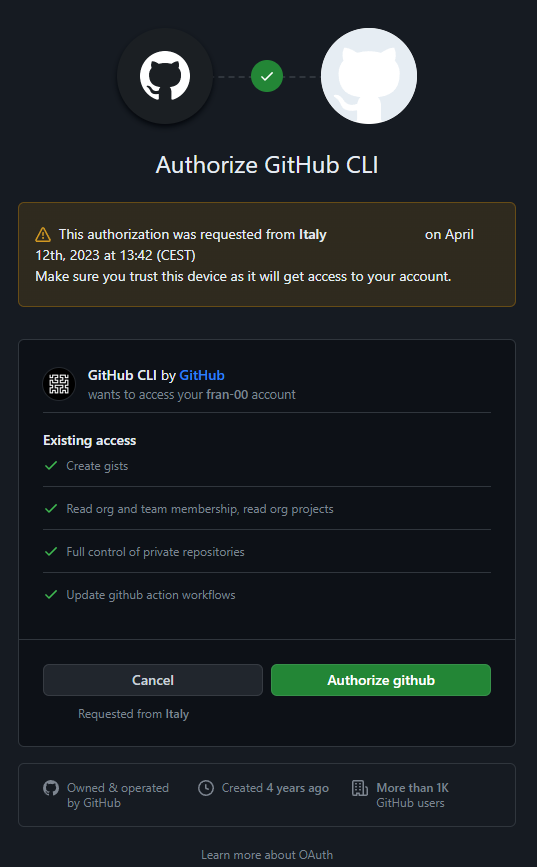
Inseriamo la nostra password di GitHub:
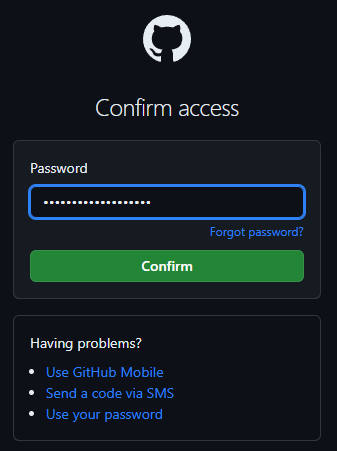
E abbiamo fatto! Adesso dovrebbe essere tutto pronto per usare Git con GitHub.
I comandi di Git
Prima di parlare di come utilizzare Git nella pratica, dobbiamo prendere un po’ di confidenza con i suoi comandi principali. Utilizzare Git non è difficile, ma ci sono moltissime funzionalità da conoscere e imparare a padroneggiare! Cerchiamo di farci un’idea di tutto quello che possiamo fare con Git vedendo nel dettaglio il funzionamento dei seguenti comandi:
- git init
- git add
- git commit
- git log
- git push
- git pull
- git fetch
- git clone e i fork
- git branch e git checkout
- git merge
- git status
- git revert
- git reset
Dopo aver visto una panoramica dei comandi più comuni vedremo degli esempi concreti su come utilizzarli. Potreste dover rivedere i vari comandi più volte, per comprenderne il funzionamento nel dettaglio. Tuttavia come precisato a inizio articolo, molti di questi saranno più semplici da memorizzare dopo aver fatto delle prove. Ricordatevi quindi di usare questa sezione come referenza.
Il comando git init
Il comando git init è utilizzato per inizializzare un nuovo repository Git vuoto nella cartella corrente. Crea una nuova directory .git (nascosta) che contiene tutti i file di configurazione e i metadati necessari per gestire il repository.
git initUna volta che il repository è stato inizializzato, possiamo aggiungere dei file tramite il comando git add.
Il comando git add
Il comando git add è utilizzato per aggiungere le modifiche al prossimo commit. Come vedremo tra poco, i commit rappresentano una sorta di “istantanea” del repository e descrivono le modifiche che abbiamo fatto. Queste modifiche possono riguardare tutto il progetto, come cambiamenti del codice, creazione o cancellazione di nuovi file o cartelle ecc., e il comando non le salva direttamente nel repository locale o remoto, ma le prepara aggiungendole ad una "staging area", ovvero una sorta di "area temporanea". Una volta aggiunte le modifiche a quest’area, è possibile effettuare il commit.
Per aggiungere file specifici alla staging area utilizziamo il seguente comando:
git add nome_filePer aggiungere tutti i file del progetto (nuovi o modificati) alla staging area:
git add .ATTENZIONE: è vivamente sconsigliato l'uso indiscriminato del comando git add .! Aggiungere modifiche al progetto non correlate tra loro crea confusione e rende difficile tenere traccia di che cosa abbiamo modificato e perché. Per questo motivo, escludendo situazioni specifiche, è consigliabile utilizzare il comando git add in modo selettivo, aggiungendo solo i file che sono stati modificati o aggiunti e che devono essere inclusi nel prossimo commit in quanto facenti parte dello stesso insieme di modifiche al progetto.
Il file .gitignore
Per escludere file e cartelle contenuti nel progetto dall’azione di git add, dobbiamo creare un nuovo file chiamato .gitignore e inserire al suo interno tutto ciò che non vogliamo includere nel repository, come ad esempio file JSON contenenti password, cartelle di ambienti virtuali, file di cache eccetera. I file elencati in .gitignore non verranno sincronizzati con il repository remoto.
In questo repo GitHub potete trovare una collezione di template di .gitignore da inserire nei vostri progetti in base al linguaggio di programmazione che utilizzate: ad esempio questo è quello per Python, impostato quindi per escludere file e cartelle comuni a progetti creati con questo linguaggio:
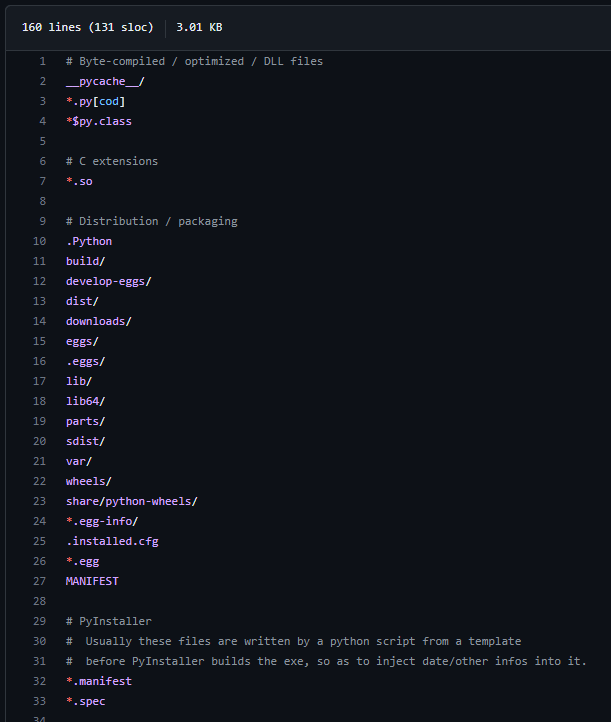
Creando un nuovo repository direttamente da GitHub come vedremo a fine articolo, avrete la possibilità di scegliere un file .gitignore appropriato.
Come rimuovere un file dalla staging area
Può capitare di aggiungere un file con git add e poi accorgersi di non volerlo includere nel commit. In tal caso possiamo utilizzare il comando git reset per annullare l’aggiunta del file specificato:
git reset nome_fileIl comando git reset ha anche altri utilizzi, ma in questo caso fa l'esatto opposto di quello che fa git add. Se utilizziamo il comando senza alcun parametro opzionale, tutti i file che sono attualmente nella staging area (l'area temporanea) verranno rimossi da essa. Eventuali modifiche apportate al progetto o al contenuto dei file non verranno però annullate e potranno quindi essere "ri aggiunte" con git add.
Il comando git commit
Una delle funzionalità più utili e importanti di Git sono i commit. Un commit (in italiano potremmo tradurlo con “impegno”) rappresenta una singola modifica apportata al contenuto del progetto. Tipicamente queste modifiche saranno di tipo testuale come l'aggiornamento del codice sorgente di un file .py o .js, ma possono rappresentare anche l'aggiunta o la rimozione di altre tipologie di file come ad esempio immagini di un sito web. Quando si crea un commit in Git, si selezionano i file che si desidera includere e si aggiunge un messaggio che descrive le modifiche apportate.
git commit -m "UPDATE post views to convert markdown post content to HTML"Quando il commit viene creato, Git crea un hash univoco per identificarlo attraverso l’algoritmo SHA, che associa una stringa di 40 caratteri a ciascun commit nel repository.
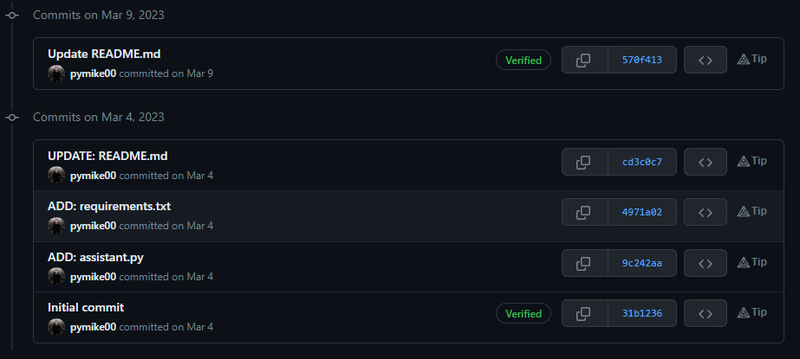
Nell’immagine possiamo vedere lo storico dei commit caricati su GitHub nel repo di Python ChatGPT: a sinistra abbiamo il messaggio di commit con la data e il nome dell’utente che lo ha effettuato, mentre a destra vediamo i primi 7 caratteri degli hash e il pulsante <>, con cui possiamo accedere ai file del repository e vedere come erano nel punto della cronologia in cui abbiamo effettuato quello specifico commit.
In questo modo è molto semplice tenere traccia di tutte le modifiche apportate a un repository! Inoltre, uno degli aspetti più utili dei commit di Git è che sono reversibili: se si commette accidentalmente un errore, è possibile annullare il commit e ripristinare il codice allo stato precedente.
Come scrivere il messaggio di commit
Scegliere con cura il messaggio che descrive il commit è fondamentale per la gestione del repository, sia per noi che lo scriviamo, sia per coloro che eventualmente stanno lavorando al nostro stesso progetto e dovranno leggerlo. Un messaggio di commit preciso e chiaro consente di comprendere facilmente le modifiche effettuate e il motivo per cui sono state apportate: ciò potrebbe rivelarsi incredibilmente utile non solo quando collaboriamo con altri, ma anche in fase di debugging del nostro stesso codice! Ma come si scrive un buon messaggio di commit?
- Meglio se in inglese: è la lingua predominante nel mondo dell'informatica ed è più facile farsi capire da tutti, soprattutto se si collabora a un progetto con persone provenienti da diverse parti del mondo.
- Dovrebbe iniziare con una parola chiave esplicativa che descriva il tipo di modifica che si sta implementando. Alcune delle parole chiave più utilizzate sono: Add, Merge, Fix, Remove, Update, Change, Refactor, Hide, Test, ecc.
- Bisogna utilizzare l’indicativo presente: ad esempio scriviamo “Add” e non “Added”.
- Deve essere specifico: dovrebbe descrivere esattamente le modifiche apportate e non dovrebbe essere mai generico o vago come "Aggiornamenti vari". Ad esempio potremmo scrivere un commit come “ADD get_URL method to View class”, ovvero "Aggiunge il metodo get_URL alla classe View".
- Deve essere conciso e andare dritto al punto, evitando di includere informazioni superflue o dettagli non pertinenti.
Tenete comunque a mente che ciascun progetto open source o team di lavoro potrebbe avere delle linee guida di riferimento che hanno comunque sempre precedenza.
Il comando git log
Per visualizzare la cronologia dei commit di un repository, possiamo andare sul sito dell’hosting che lo ospita, come GitHub, oppure utilizzare direttamente il comando git log:
git logIl comando ci mostrerà nel terminale una lista dei commit nell'ordine in cui sono stati effettuati, insieme ai relativi metadati come l'autore, la data, il messaggio di commit e l'hash:
Author: fran-00 <XXXXXX@XXX.com>
Date: Thu Apr 13 17:06:24 2023 +0200
Add Python .gitignore template
commit 614d165aba121911ec63312fea388f4d8079c1aePer uscire dalla lista dei commit, premiamo il tasto “Q”.
Il comando git push
Il comando git push è utilizzato per caricare i commit locali su un repository remoto. Con questo comando aggiorniamo i file contenuti nel repository con le modifiche che abbiamo fatto in locale e facciamo in modo che gli altri membri del team con cui eventualmente stiamo collaborando possano accedervi e integrarle alla loro versione del codice.
Se non utilizziamo questo comando, le modifiche apportate verranno mantenute solo nel repository locale e non saranno accessibili da remoto.
git pushQuando si esegue il comando git push su un repository che non è di proprietà dell'utente, è necessario disporre delle autorizzazioni per accedere: se lo eseguiamo senza avere i permessi di scrittura, il comando git push restituirà un errore e non invierà le modifiche. In questo caso, potrebbe essere necessario creare un fork del repository e inviare una pull request per richiedere (o suggerire!) l'integrazione delle modifiche: vedremo a breve che cosa significa.
Il comando git pull
Il comando git pull esegue l’operazione inversa a quella di git push: è utilizzato per recuperare le modifiche dal repository remoto e integrarle con il repository locale in modo da avere l'ultima versione del progetto.
git pullSe non utilizziamo il comando quando lavoriamo a un progetto in collaborazione con altri, il repository locale potrebbe diventare obsoleto rispetto a quello remoto e potrebbero verificarsi conflitti tra le modifiche apportate.
Che cos’è una pull request?
Quando si vuole contribuire a un repository che non è di nostra proprietà, possiamo creare un fork del repository, apportare le modifiche necessarie e quindi inviare una pull request al proprietario del repository originale. Questi può quindi esaminare le modifiche, discutere eventuali problemi e decidere se accettare o meno: se la pull request viene accettata, le modifiche vengono integrate nel repository originale.
Il comando git fetch
Abbiamo visto che il comando git pull sincronizza il repository remoto con quello che abbiamo in locale. Se vogliamo solo scaricare e visualizzare le modifiche senza applicarle automaticamente, usiamo il comando git fetch (in italiano "raggiungere" o "andare a prendere"):
git fetchSe accettiamo le modifiche e vogliamo applicarle alla copia locale possiamo usare semplicemente il comando git pull.
Il comando git clone e i fork
Il comando git clone consente di scaricare l'intero repository dal repository remoto e creare una copia locale sul proprio computer. Questa copia sarà comprensiva di tutti i file, la cronologia dei commit e le informazioni di configurazione in un determinato momento dello sviluppo del progetto. È possibile usare il comando git clone sia sui propri repository che su quelli pubblici di altri developer.
Quando si utilizza il comando bisogna specificare l'URL del repository remoto che si vuole clonare. Ad esempio, creiamo una copia locale del repository "jerry" da quello remoto su GitHub:
git clone https://github.com/username/jerry.gitSu GitHub possiamo ottenere il comando sopra descritto automaticamente, cliccando sull'apposito tasto verde.
Quando si clona un repository viene creato un collegamento tra il repository locale e quello remoto, identificato dal nome origin (in italiano “origine”), che è il termine usato per riferirsi al repository remoto da cui è stato clonato il repository locale. Sarà possibile esplorare il codice e i file del progetto, così come anche eseguire il codice, come se ci si trovasse nel computer degli sviluppatori.
I Fork
Se si pensa che un progetto pubblico sviluppato da altri developer sia particolarmente interessante, e si intende apportare delle modifiche personali volendole poi salvare, ad esempio per far si che il codice di un progetto open source venga adattato ad un vostro specifico caso d'uso, è possibile creare un fork (una "biforcazione") del progetto. Il fork è una copia indipendente del repository e sarà abbinata al vostro profilo GitHub, da cui potrete accedervi.
L'utente che ha forkato il repository può ora lavorare sulla propria copia, creare nuovi branch e apportare modifiche a questi senza dover notificare i creatori del progetto originario.
Se si intende condividere le proprie modifiche col progetto originale in modo che vengano unite al ramo principale del progetto forkato (il branch main) sarà possibile inviare una pull request ai creatori del progetto originale. Con questo processo è possibile collaborare in team per progetti di sviluppo anche molto grandi:
- Creare un fork del progetto su GitHub
- Clonare il repo del fork sul proprio computer
- Creare un branch su cui apportare delle modifiche
- Salvare le modifiche via commit nel branch
- Pubblicare le modifiche sul ramo del proprio fork via push
- Aprire una pull request
Nota: è importante seguire sempre raccomandazioni e linee guida specifiche per ogni progetto prima di proporre delle modifiche per l'aggiunta al repo originale.
I comandi git branch e git checkout
Come i commit, i branch sono un altro concetto fondamentale di git. Un branch (in italiano “ramo”) è una linea di sviluppo separata all'interno di un repository e consente di fare delle modifiche senza influire sul codice principale, che si reputa generalmente il più stabile e adatto all'utilizzo in produzione.
Quando si lavora a un progetto complesso, diverse funzionalità o correzioni di bug possono essere sviluppate contemporaneamente da più sviluppatori. Per evitare di interferire con il lavoro degli altri o per testare in sicurezza dei possibili aggiornamenti è possibile creare un branch separato dal main branch per ogni nuova funzionalità o correzione di bug: in questo modo tutte le modifiche apportate a quel branch sono separate da quelle apportate agli altri. main o master sono i nome di default dati al ramo principale dei progetti.
Ad esempio, per creare un branch separato per implementare la feature-X, scriviamo:
git branch feature-XDopo aver usato il comando git branch come sopra mostrato, provando a dare il comando git status (che vedremo nel dettaglio più avanti) ci renderemo conto di trovarci ancora nel rampo principale main.
Per spostarci su questo nuovo ramo possiamo usare il comando git checkout:
git checkout feature-XDando il comando git status vedremo ora che ci si trova sul ramo feature-X, e qualsiasi commit sarà ora abbinato a questa linea di sviluppo separata.
In questo modo, gli sviluppatori possono lavorare in modo indipendente sui loro rami di sviluppo senza interferire con il lavoro degli altri. Una volta completato il lavoro, il ramo di sviluppo può essere unito al ramo principale tramite il comando git merge.
Il comando git merge
Per combinare le modifiche di due branch in uno solo, utilizziamo il comando merge (in italiano "unione", "fusione").
Per effettuare un merge, dobbiamo dire al comando quale ramo vogliamo unire a quello in cui stiamo attualmente lavorando. Ad esempio se ci troviamo in main, possiamo effettuare il merge del ramo feature-X inviando il comando:
git merge feature-XTipicamente si sviluppano le modifiche in un branch isolato e quando si arriva ad un punto in cui ci si ritiene soddisfatti del codice scritto, perché funzionale e stabile, ci si sposta sul ramo principale e si effettua il merge.
Git cercherà di unire le modifiche apportate in maniera automatica, aspettandosi quindi implicitamente un certo livello di disciplina e rigore nel processo di sviluppo. In caso di conflitti che possono tuttavia emergere, perché magari due rami stanno lavorando contemporaneamente sugli stessi file, Git richiede all'utente di risolverli manualmente scegliendo quale modifica tenere e quale scartare.
Il comando git status
Possiamo visualizzare lo stato del repository Git tramite il comando git status, che ci permette di accedere a diverse informazioni sul nostro repository, tra cui:
- Il branch corrente e il commit più recente.
- I file che sono stati modificati ma che non sono ancora stati aggiunti alla staging area.
- I file che sono stati aggiunti alla staging area, ma di cui ancora non si è effettuato il commit.
- I file che sono stati eliminati dalla working directory, ma non sono stati ancora eliminati dalla staging area.
Il comando è fondamentale per tenere traccia delle modifiche apportate ai file nel repository e per verificare lo stato corrente del branch. Ad esempio, se non abbiamo modificato nessun file, git status ci dirà solo in quale branch ci troviamo:
On branch main
Your branch is up to date with 'origin/main'.
nothing to commit, working tree cleanSe invece modifichiamo un file, ci dirà le informazioni sul file e sulla modifica:
On branch main
Your branch is up to date with 'origin/main'.
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: README.md
no changes added to commit (use "git add" and/or "git commit -a")Il comando git revert
Abbiamo detto che una delle maggiori comodità di Git è quella di poter annullare le modifiche apportate in precedenza a un repository: per farlo, utilizziamo il comando git revert. Il comando non elimina il commit precedente, ma ne crea uno nuovo che annulla le modifiche apportate: la cronologia dei commit rimane intatta e il commit originale rimane nel repository.
Per utilizzare il comando git revert, dobbiamo specificare l'hash del commit che vogliamo annullare. Ad esempio, per annullare il commit con l'hash xyzt421, eseguiamo il seguente comando:
git revert xyzt421Git aprirà un file di testo per inserire un messaggio di commit e, una volta salvato, creerà un nuovo commit che annulla le modifiche apportate nel commit specificato.
ATTENZIONE: è bene utilizzare questo comando con cautela. Ad esempio, se il commit che si sta cercando di annullare ha modificato anche altri file o parti di codice, l'operazione di revert potrebbe causare effetti imprevisti. Quindi è fondamentale sapere esattamente cosa si sta annullando e come git revert influirà sul resto del progetto!
Il comando git reset
Quando abbiamo parlato del comando git add, abbiamo visto che per rimuovere i file dalla staging area si utilizza il comando git reset. Questo comando ha anche diversi altri utilizzi: possiamo usarlo per annullare gli ultimi commit che abbiamo già inviato, spostare un branch a un commit precedente, ripristinare un file e molto altro. Ad esempio, per annulare l'ultimo commit effettuato nel branch corrente mantenendo le modifiche apportate ai file, possiamo usare git reset come segue:
git reset HEAD~1In questo modo possiamo fare correzioni al commit annullato e quindi effettuare un nuovo commit con le modifiche corrette.
ATTENZIONE: questo comando va utilizzato con estrema cautela perché se usato con alcune opzioni è in grado di modificare lo stato del repository remoto e fare danni! Se usato indiscriminatamente potrebbe influenzare anche il lavoro degli sviluppatori che stanno collaborando al progetto con noi e che magari hanno già scaricato le modifiche che noi stiamo annullando e le hanno applicate al loro codice!
Il file HEAD
Nei comandi e nel log abbiamo visto che viene utilizzato il termine HEAD: si tratta di un file contenuto nella cartella del repository .git che rappresenta un riferimento al branch in cui ci troviamo attualmente. Se ci troviamo nel branch main, questo sarà il contenuto di HEAD:
ref: refs/heads/mainSe cambiamo branch, cambierà il riferimento:
ref: refs/heads/other-branchEsempi di utilizzo di Git
Vediamo ora una serie di utilizzi comuni di Git e GitHub. Ci ritroveremo a fare molto spesso queste operazioni se decidiamo di utilizzare Git come sistema di controllo di versione:
- Creare un nuovo repository su GitHub
- Eseguire un commit
- Scaricare modifiche da un repository remoto
- Creare un nuovo branch
- Eseguire il merge di un branch
Creare un nuovo repository su GitHub
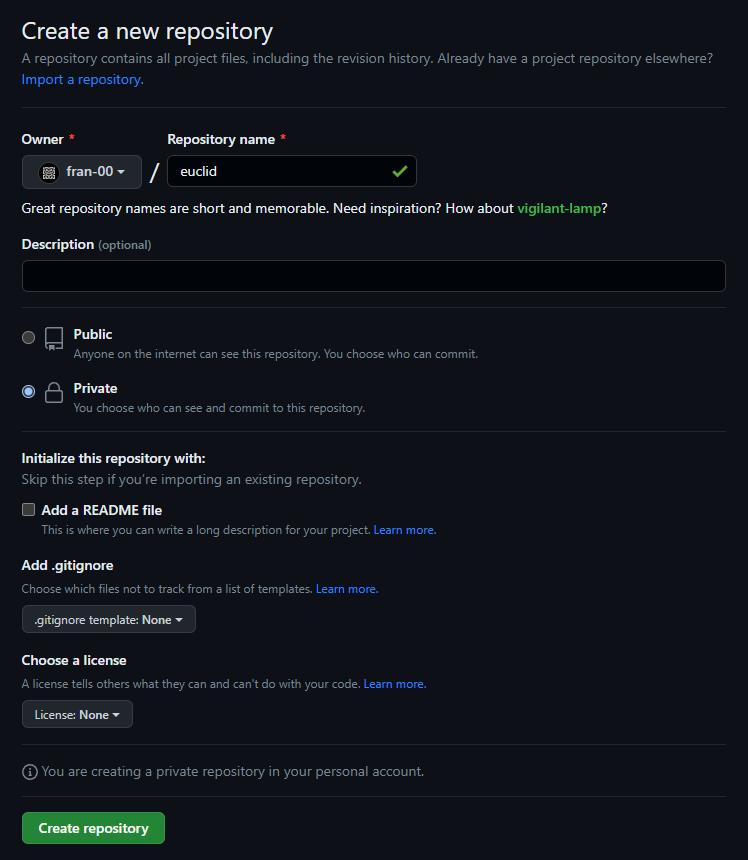
Andiamo sul sito di GitHub e clicchiamo sul + nella barra di navigazione in alto a destra nella pagina e selezioniamo la voce “New Repository”. Scegliamo un nome per il nostro repo (in questo caso l’ho chiamato euclid) e se renderlo pubblico o privato.
Come notate abbiamo anche l'opzione per generare automaticamente un file README.md e un file .gitignore compatibile con la tipologia di progetto che stiamo sviluppando. Abbiano inoltre la possibilità di scegliere una tipologia di licenza open source.
Una volta impostati i parametri che più riteniamo opportuni clicchiamo sul pulsante “Create repository”.
GitHub a questo punto mostrerà una schermata con vari comandi. Possiamo semplicemente clonare il repository, impostarlo come host remoto per un repository già presente nel nostro sistema ed altro ancora.
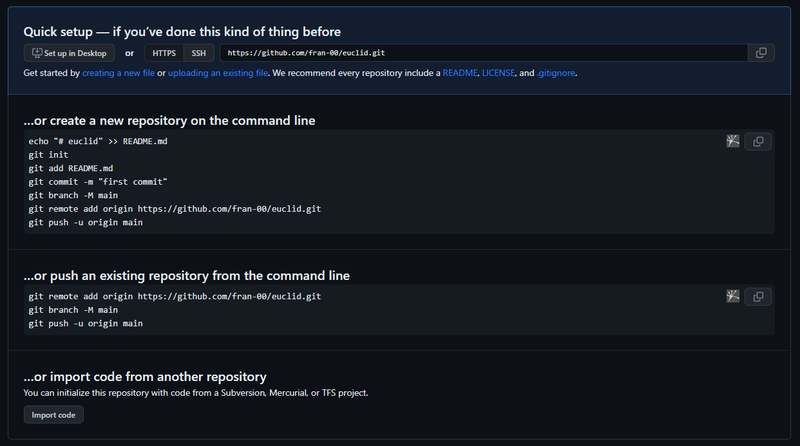
Il workflow d'utilizzo più comune prevede l'utilizzo del comando git clone sullo url del repo appena creato su GitHub. Una volta clonato il progetto sul nostro computer possiamo iniziare a scrivere codice con una progressione di commit, che potranno quindi essere caricati anche su GitHub man mano che apportiamo nuove modifiche.
Tuttavia, se vi state avvicinando da poco all'uso di git, potreste verosimilmente avere delle bozze di file più o meno sviluppate da usare come base di partenza per il vostro nuovo progetto, e che vanno quindi aggiunte al progetto.
Ipotizziamo di avere un semplice script chiamato triangle_inequality.py contenente una funzione che verifica la disuguaglianza triangolare per tre numeri interi positivi:
def disuguaglianza_triangolare(a: int, b: int, c: int) -> bool:
if (a + b > c) and (a + c > b) and (b + c > a):
return True
else:
return False
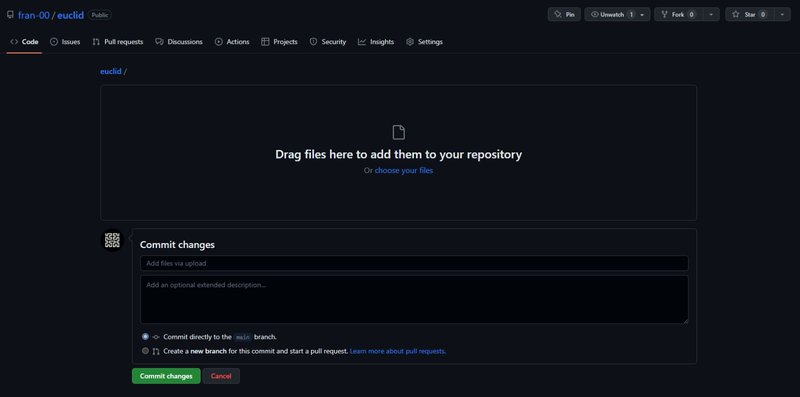
disuguaglianza_triangolare(2, 8, 3)Visto che abbiamo già dei file che sappiamo ci serviranno sicuramente, prima di dare il comando git clone sul nostro repo, partendo dalla stessa schermata con tutti i comandi mostrata da GitHub che abbiamo appena visto, clicchiamo su "upload an existing file" per avere accesso ad una schermata di caricamento file con drag and drop.
Trasciniamo il file triangle_inequality.py per effettuare l'upload. Clicchiamo quindi il tasto verde "commit changes".
Ora non ci resta che scaricare il repo correttamente inizializzato, aprire la cartella appena scaricata su un editor testuale, e iniziare a sviluppare:
git clone https://github.com/fran-00/euclid.gitEseguire un commit
Modifichiamo la copia locale del nostro file triangle_inequality.py in qualche modo. Io ho aggiunto una riga di codice per chiedere una stringa di tre numeri come input all’utente. Viene quindi utilizzato il metodo split() per suddividerla in tre parti separate e la funzione map() per convertire i numeri da stringhe a interi con int().
a, b, c = map(int, input("Inserisci tre numeri separati da uno spazio: ").split())Ora, se da dentro la cartella del repo diamo il comando git status l’output ci dirà che il file è stato modificato ma non è stato ancora aggiunto alla staging area:
On branch main
Your branch is up to date with 'origin/main'.
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: triangle_inequality.py
no changes added to commit (use "git add" and/or "git commit -a")Aggiungiamo quindi alla staging area il nostro file col comando git add:
git add triangle_inequality.pyAdesso il comando git status ci dirà che il file è stato aggiunto alla staging area ed è pronto per il commit:
On branch main
Your branch is up to date with 'origin/main'.
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
modified: triangle_inequality.pySe siamo soddisfatti dei cambiamenti apportati possiamo quindi effettuare un commit. Usiamo il comando git commit aggiungendo il flag “-m”, e scriviamo il messaggio di commit direttamente da riga di comando. Ricordiamo che il messaggio di commit dovrebbe sempre descrivere le modifiche apportate in maniera breve ma efficace.
git commit -m "Add user input for three numbers using map function"Per aggiornare il repository remoto con le modifiche che abbiamo fatto, diamo il comando git push. Tornando su GitHub ed esplorando il repository noteremo ora che i cambiamenti sono stati salvati anche in remoto!
Scaricare modifiche da un repository remoto
Visto quanto abbiamo detto finora soprattutto in merito allo sviluppo collaborativo, è verosimile pensare che il repository GitHub possa essere più aggiornato rispetto a quello presente nel nostro computer. Adesso vedremo quindi come scaricare le modifiche dal repository remoto e applicarle a quello locale, creando come esempio un nuovo file Markdown direttamente da GitHub.
Ogni repository dovrebbe avere un file README.md al suo interno: il suo scopo principale è quello di descrivere il progetto, le sue funzionalità e fornire le istruzioni per installare il software. Il file verrà mostrato automaticamente nella home page del repository e chiunque abbia accesso potrà leggerlo.
Creiamo il file README.md direttamente da GitHub premendo il tasto con scritto “Add File” all’interno del repository, ci troveremo davanti a questa schermata:
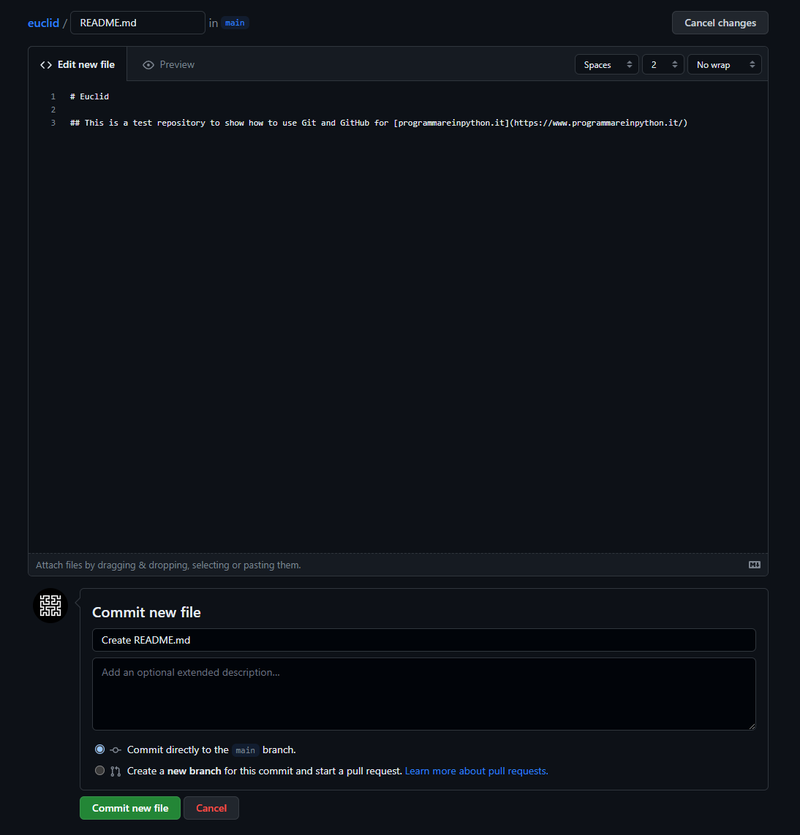
Scriviamo il messaggio di commit e premiamo il tasto verde: adesso sul repo remoto c’è un file che non abbiamo in locale! Che fare per poterlo avere anche in locale?
Come forse avrete intuito a questo punto, diamo il comando git pull: il file verrà scaricato e saremo sincronizzati con il repo remoto.
Modifichiamo di nuovo README.md dall’interfaccia di GitHub aprendolo e premendo sulla matita o aprendo il menù a tendina:
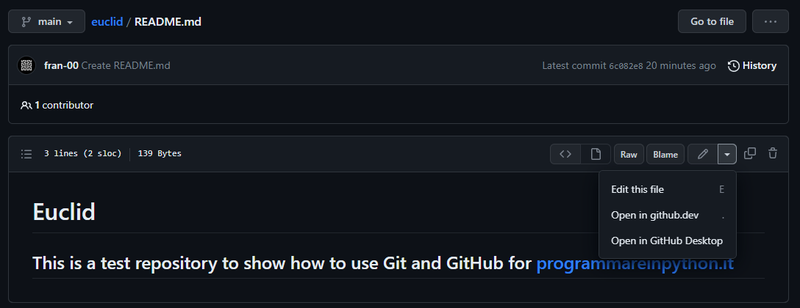
Modifichiamo il file in qualsiasi modo e descriviamo nel messaggio di commit la nostra modifica. Io ho aggiunto il grassetto alle parole “Git” e “GitHub”, quindi come messaggio ho scritto: “Update Git and GitHub names with bold formatting”.
A questo punto il repo remoto è nuovamente aggiornato rispetto a quello locale. Ma che fare se non abbiamo accesso a GitHub per qualsiasi motivo, volendo verificare le modifiche apportate prima di unirle alla nostra copia locale?
Ci serviranno due comandi. Anzitutto usiamo git fetch per scaricare le modifiche senza applicarle automaticamente. Usiamo quindi git diff per evidenziare le modifiche tra il nostro branch main e il repo remoto:
git diff origin/mainIl terminale ci mostrerà esattamente quale modifica abbiamo scaricato indicandoci il nome del file, la posizione della modifica nel file e la modifica stessa.
diff --git a/README.md b/README.md
index 8e9c318..c3743a7 100644
--- a/README.md
+++ b/README.md
@@ -1,3 +1,3 @@
# Euclid
-## This is a test repository to show how to use **Git** and **GitHub** for [programmareinpython.it](https://www.programmareinpython.it/)
+## This is a test repository to show how to use Git and GitHub for [programmareinpython.it](https://www.programmareinpython.it/)Adesso che sappiamo di voler integrare le modifiche apportate su GitHub, se diamo il comando git pull come abbiamo già visto negli esempi precedenti il nostro repo locale sarà sincronizzato con quello remoto.
Updating 6c082e8..03f0ce7
Fast-forward
README.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)Se utilizziamo il comando git log, vedremo i nostri commit:
commit 03f0ce7a6574346ed373f09992c33503b800d1cd (HEAD -> main, origin/main)
Author: fran-00 <76666632+fran-00@users.noreply.github.com>
Date: Wed Apr 12 07:48:32 2023 +0200
Update Git and GitHub names with bold formatting
commit 6c082e820e889dcc12275ac80ca25d6d646f7d3b
Author: fran-00 <76666632+fran-00@users.noreply.github.com>
Date: Wed Apr 12 07:22:50 2023 +0200
Create README.mdCreare un nuovo branch
Creiamo un nuovo branch per il nostro repository euclid. Chiamiamolo “turtle-implementation” perché la funzionalità che vogliamo implementare in futuro sarà quella di utilizzare il modulo turtle per disegnare un triangolo qualora la disuguaglianza triangolare sia rispettata:
git branch turtle-implementationLe modifiche che abbiamo fatto finora le abbiamo tutte caricate sul branch principale, ovvero su main. Spostiamoci sul branch che abbiamo appena creato in questo modo:
git checkout turtle-implementationIn alternativa possiamo creare un nuovo branch e passare automaticamente ad esso con un solo comando aggiungendo il flag -b:
git checkout -b turtle-implementationPer pubblicare il branch nel repo remoto diamo il seguente comando:
git push origin turtle-implementationAdesso possiamo lavorare sul branch senza che le nostre modifiche influenzino il main. Modifichiamo il nostro codice, ad esempio inserendo un import statement. Se inviamo il commit al repository remoto, andando ad aprirlo vedremo questa schermata:
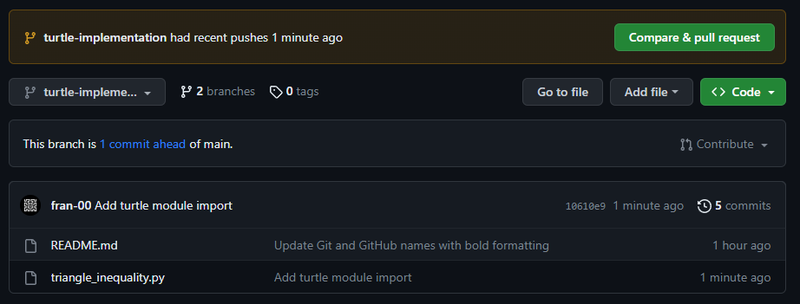
Quindi la nostra modifica è stata salvata sul branch che abbiamo creato anche nel repository in remoto. Adesso possiamo effettuare il merge e integrare la modifica nel ramo principale direttamente da qui premendo il pulsante verde “Compare & pull request” oppure da terminale, vediamo in che modo.
Eseguire il merge di un branch
Facciamo un’altra modifica al nostro codice, io modificherò gli argomenti della funzione disuguaglianza_triangolare per fare in modo che il tipo di dato passato possa essere di qualsiasi tipo perché viene già convertito dalla funzione map() nell’assegnazione delle variabili. Scriviamo un messaggio di commit appropriato e inviamo con push le nostre modifiche, nel mio caso sarà “Remove type annotations from function arguments”.
Adesso proviamo ad unire il nostro branch con main. Dato che ci troviamo sul branch che vogliamo unire, spostiamoci sul branch main e poi inviamo il comando merge.
git checkout main
git merge turtle-implementationInfine, inviamo il comando per sincronizzare i commit sul branch locale con quello remoto:
git pushAdesso le modifiche fatte al branch saranno integrate nel ramo principale!
Con questo articolo abbiamo solo cominciato ad esplorare le funzionalità di Git: sono veramente tantissime e per una panoramica completa potete consultare la documentazione.
Con quello che abbiamo visto insieme dovreste esservi fatti un’idea delle funzionalità di Git e GitHub, ma molte cose le scoprirete man mano che li utilizzerete per i vostri progetti. Volendo potete trovare anche una guida super approfondita sul sito ufficiale, con tanto di video in lingua inglese!
Se volete potete trovare il codice di questa lezione nel repo.
Happy Coding!
E se potessi andare oltre?
Funzioni, Classi e OOP, decoratori, properties — tutto quello che serve per scrivere codice Python seriamente. Impara questo e molto altro nei nostri corsi completi!